


dbt 101: Modelagem de Dados + dbt = ❤️
Como organizar seu pipeline de dados segundo o playbook do dbt

Meu nome é Igor Cleto, e eu sou Engenheiro de Dados.
Neste espaço compartilho o que venho aprendendo a respeito de Dados e Tecnologia de maneira acessível e em português.
Ainda não é inscrito? Inscreva-se no botão abaixo!
Intro
Caso você ainda não conheça o Data Build Tool (dbt) e esteja construindo pipelines de dados por meio de scripts SQL avulsos, células de notebooks sem padronização de linguagem ou sem o apoio de algum outro framework, venho apresentar esta ferramenta que traz para nós, engenheiros de dados, as boas práticas de engenharia de software para dar aos nossos pipelines a robustez e a escalabilidade que eles merecem, com organização, padrões e testes de software. Afinal, um processo de Analytics é também um processo de Engenharia. Tenho escrito vários artigos sobre o dbt, mas aqui o foco está na modelagem de dados de acordo com as boas práticas que o time de engenharia de analytics do dbt defende em seu playbook.
Overview
O processo de estruturar modelos de dados com o Data Build Tool (dbt) envolve a separação dos modelos em três camadas principais, a saber: staging, intermediate e marts. Nas próximas seções, vamos nos aprofundar em cada uma dessas camadas e abordar alguns conceitos fundamentais que ajudarão você a distingui-las. Você também deverá ser capaz de identificar em qual dessas camadas deve colocar cada etapa do seu pipeline.
Neste artigo irei me restringir num contexto de pipelines de dados ELT e EtLT, padrão mais adotado atualmente no universo de Stack de Dados Moderna atrelada a Data Lakes na Cloud. (Caso você não conheça esses conceitos em breve terão novos artigos sobre estes temas).
Modelos Staging
A camada de staging é onde nossa jornada começa. Esta é a base do nosso projeto, onde trazemos todos os componentes individuais que vamos usar para construir nossos modelos mais complexos e úteis para o projeto. Os modelos staging devem ter uma relação 1-to-1 (ou mapeamento) com as tabelas fonte do nosso pipeline.
Compartilho a seguir um trecho de código da documentação oficial do dbt, no qual há um exemplo de um modelo staging bem simples que irá tangibilizar esse conceito. Temos uma tabela fonte com dados de pagamento recebidos através do sistema Stripe.
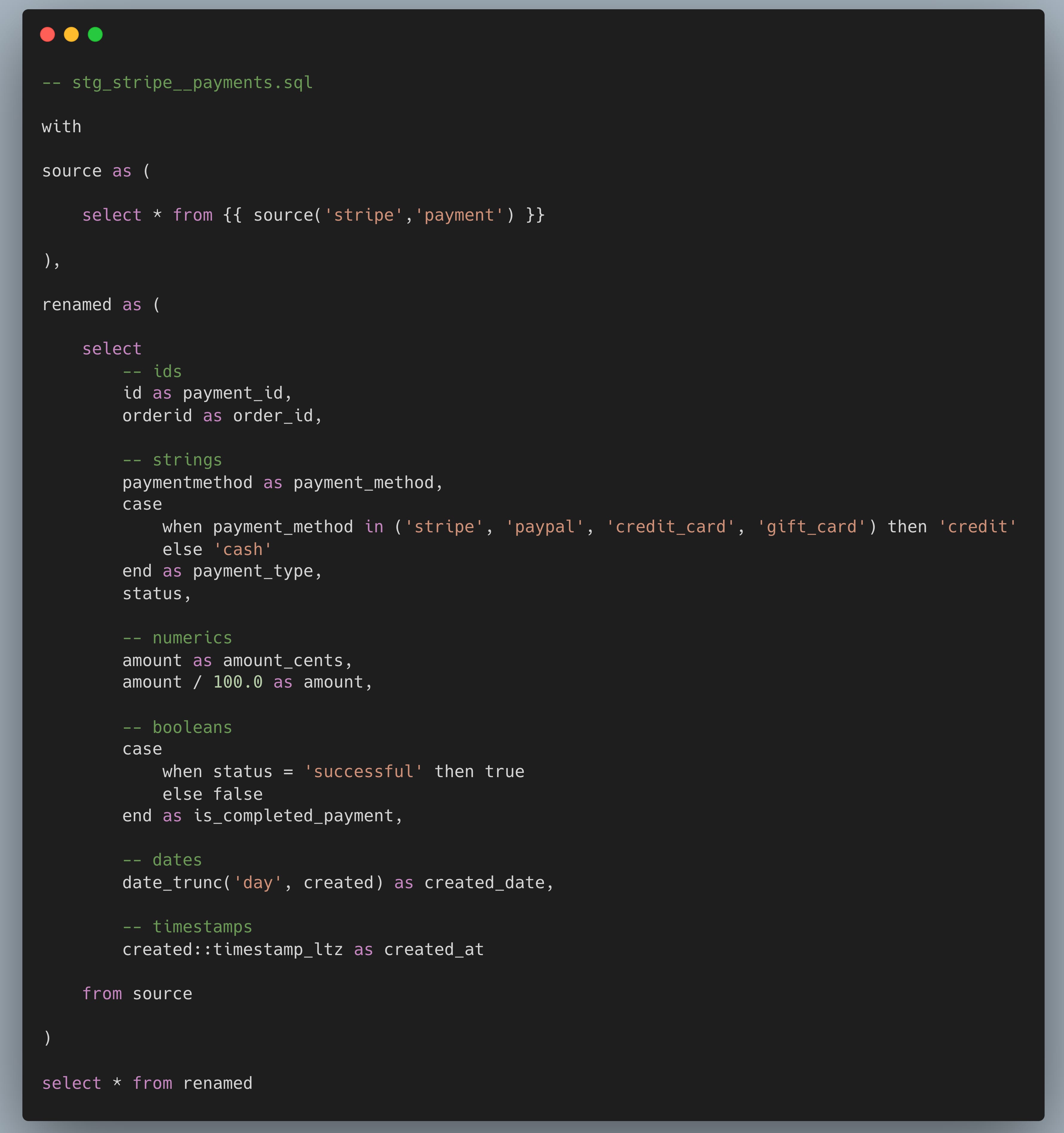
Com base no exemplo, os tipos mais padrão de transformações em modelos de staging são:
✅ Renomeação
✅ Conversão de tipos
✅ Cálculos básicos (por exemplo, de centavos para dólares)
✅ Categorização (usando lógica condicional para agrupar valores em categorias ou booleanos, como no caso das instruções when acima).
❌ Joins — o objetivo dos modelos de staging é limpar e preparar conceitos individuais conformes com a fonte. Estamos criando a versão mais útil de uma tabela do sistema de origem, que podemos usar como um novo componente modular para o nosso projeto.
❌ Agregações — agregações implicam agrupamento, e não estamos fazendo isso nesta fase. Lembre-se: modelos de staging são o seu lugar para criar o alicerce que você usará ao longo de todo o seu projeto — se começarmos a mudar o nível de granularidade das nossas tabelas agrupando nesta camada, perderemos o acesso aos dados da fonte que provavelmente precisaremos em algum momento. Queremos apenas limpar e preparar nossos conceitos individuais para uso, e lidaremos com a agregação de valores nas camadas posteriores.
Como eles não são destinados a serem artefatos finais (consumidos por stakeholders do projeto) por si só, mas sim alicerces para modelos posteriores, os modelos de staging devem, tipicamente, ser materializados como views por duas razões principais:
Dados sempre atualizados: Qualquer modelo downstream (discutido mais detalhadamente na camada de marts) que referencie nossos modelos de staging sempre obterá os dados mais recentes possíveis a partir de todas as views componentes que está reunindo e materializando.
Eficiência no armazenamento: Evita o desperdício de espaço no data warehouse com modelos que não são destinados a serem consultados diretamente pelos consumidores de dados, e, portanto, não precisam ter um desempenho tão rápido ou eficiente.
Modelos Intermediários
A camada intermediária reúne os alicerces que residem na camada de staging, de modo que modelos mais complexos e significativos sejam construídos. Embora os modelos intermediários sejam utilizados para representar conceitos mais relevantes para o lado de negócios, eles não devem ser expostos diretamente aos usuários finais por meio de dashboards ou aplicações.
Vamos a mais um exemplo:
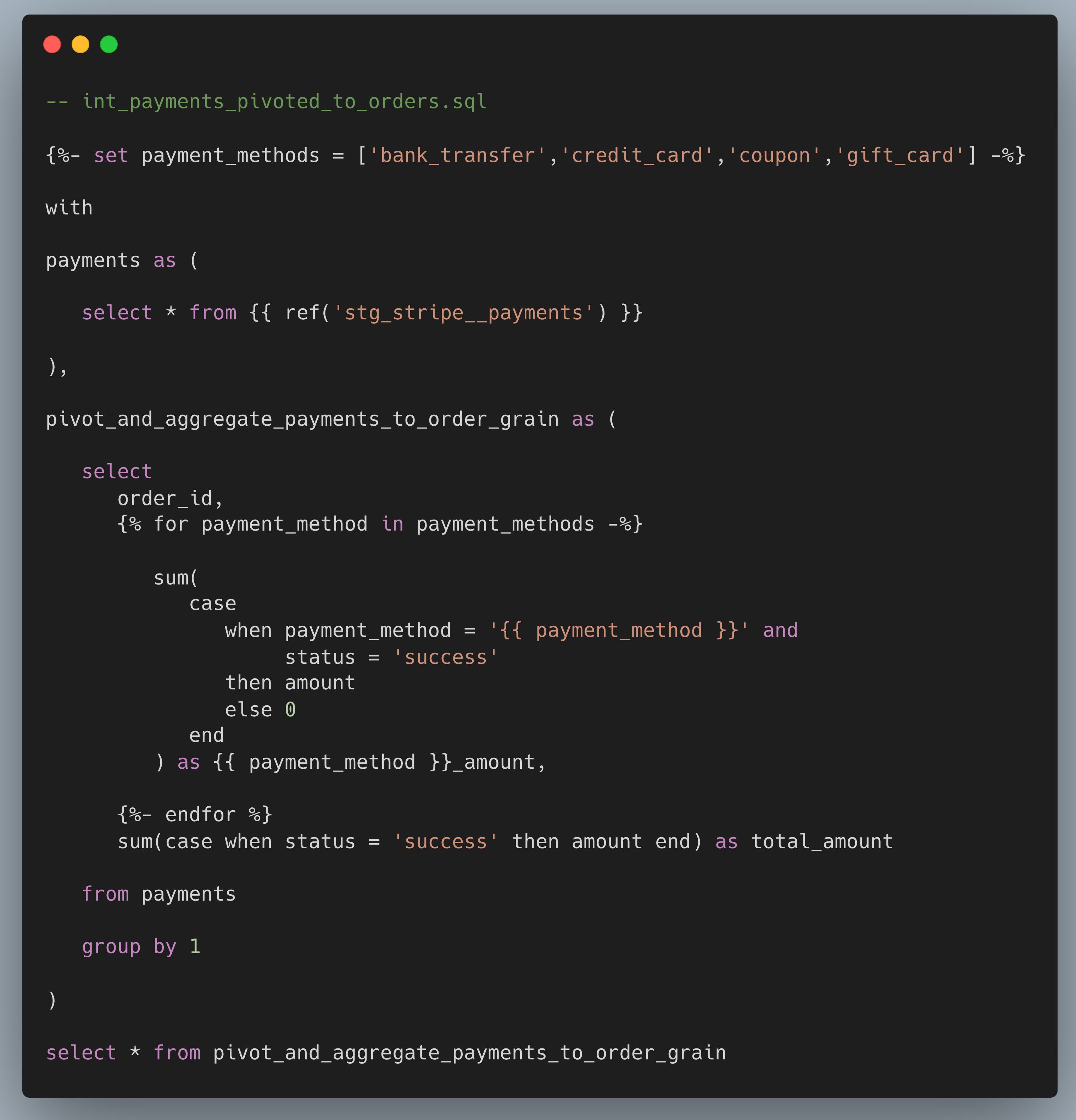
Neste caso há a transformação e agregação de dados de pagamentos para um nível de granularidade por pedido (order).
Este é um excelente caso de uso de acordo com os nossos princípios acima, pois atende a um propósito claro e específico: agrupar e fazer o pivot de um modelo de staging para uma granularidade diferente.
Devemos nos atentar aos seguintes conceitos:
❌ Expostos para usuários finais. Modelos intermediários não devem ser expostos no esquema principal de produção. Eles não são feitos para serem usados diretamente em dashboards ou aplicativos finais. Por isso, é melhor mantê-los separados dos modelos que são destinados a esses fins, para facilitar o controle da governança de dados e a organização.
✅ Materializados como efêmeros. Uma opção comum é configurar os modelos intermediários para serem materializados como efêmeros (ephemeral) no dbt. Essa abordagem é simples e mantém modelos desnecessários fora do seu data warehouse, exigindo pouca configuração. No entanto, vale lembrar que, por serem incorporados diretamente nos modelos que os utilizam, os modelos efêmeros podem dificultar um pouco o processo de debugging, já que não geram tabelas ou views que possam ser analisadas separadamente.
Modelos efêmeros são únicos porque não criam nenhuma representação física no banco de dados. Quando um modelo é configurado como efêmero, o dbt incorpora diretamente o código SQL desse modelo em qualquer outro modelo que o referencie. Isso permite que transformações intermediárias sejam abstraídas sem a necessidade de criar tabelas ou views intermediárias, evitando, assim, o custo adicional de armazenamento no banco de dados.
✅ Materializados como views em um esquema personalizado com permissões específicas. Uma alternativa mais robusta é materializar os modelos intermediários como views em um esquema personalizado, separado do esquema principal de produção. Isso facilita o acompanhamento durante o desenvolvimento e torna a resolução de problemas mais simples à medida que a quantidade e a complexidade dos modelos aumentam.
Se você ainda não tem certeza se precisa criar um modelo intermediário, lembre-se de que a camada intermediária é composta por modelos que reúnem diferentes entidades para absorver a complexidade dos modelos finais (marts). Além disso, eles devem ser usados de forma a manter ou até mesmo facilitar a legibilidade e a flexibilidade dos nossos componentes.
Por fim, uma boa regra prática é observar com que frequência um modelo intermediário é referenciado em outros modelos. Se o mesmo modelo intermediário for referenciado por mais de um modelo, isso pode indicar um problema no design. Esse tipo de situação geralmente sugere que talvez seja mais apropriado transformar o modelo intermediário em uma macro.
Modelos Mart
A camada superior e final deve incluir os chamados modelos mart. Em outras palavras, é aqui que tudo se reúne para construir entidades definidas pelo negócio, que são disponibilizadas de forma prática para os usuários finais, seja por meio de dashboards ou aplicações.
Também pode ser chamada de camada de entidade ou camada de conceito, para enfatizar que todos os nossos marts devem representar uma entidade ou conceito específico em sua granularidade única. Por exemplo, um pedido, um cliente, um território, um evento de clique, um pagamento — cada um desses seria representado por um mart distinto, onde cada linha corresponderia a uma instância única desses conceitos.
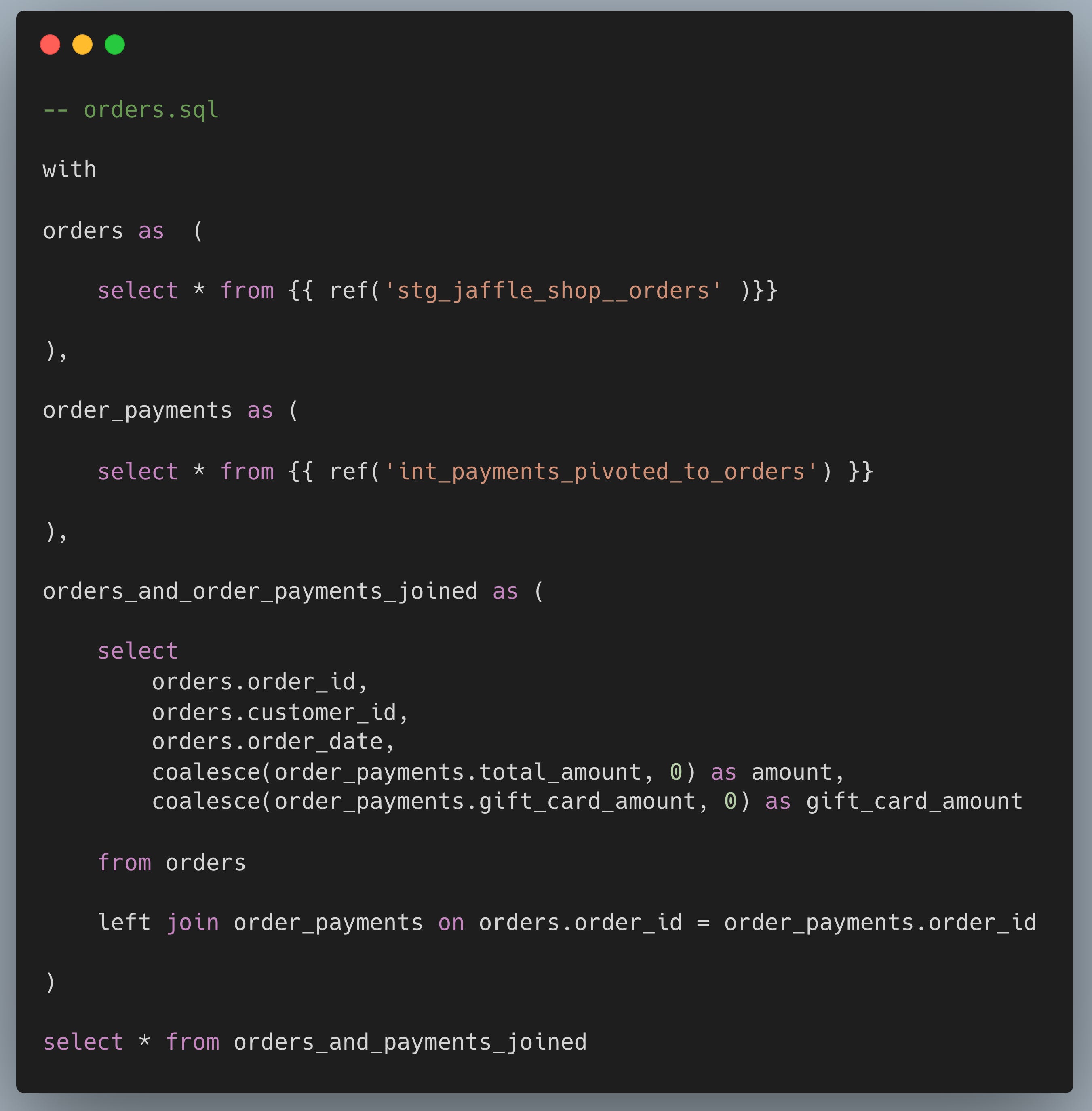
✅ Materializado como tabelas ou modelos incrementais.
Na camada de marts, é hora de não apenas implementar a lógica no data warehouse, mas também armazenar os próprios dados. Isso oferece aos usuários finais um desempenho muito mais rápido nos modelos criados para uso direto e reduz custos de recomputação ao atualizar dashboards ou executar modelos de Machine Learning.
Os modelos com maior volume de dados e transformações computacionalmente intensivas devem aproveitar as opções incrementais do dbt. Porém, transformar todos os modelos de mart em incrementais por padrão pode introduzir dificuldades desnecessárias. Entender a necessidade do time de negócios e adaptar o pipeline para a sua realidade é sempre o melhor caminho.
✅ Construa marts separados com cuidado.
Um exemplo comum é passar informações entre marts com granularidades diferentes, como levar o mart de pedidos (orders) para o mart de clientes, agregando dados importantes de pedidos na granularidade de clientes.
❌ Muitos joins em um único mart.
Uma boa prática ao criar transformações no dbt é evitar consolidar muitos conceitos em um único mart.
O ideal é balancear o número de modelos combinados com a complexidade lógica do mart. Se a leitura e compreensão do mart ficar confusa, considere modularizar. Por exemplo, dois modelos intermediários que unem três conceitos cada e um mart que combina esses dois modelos intermediários criam uma cadeia de lógica mais clara e legível do que um mart único com seis joins. Usar um mart para construir outro é permitido.
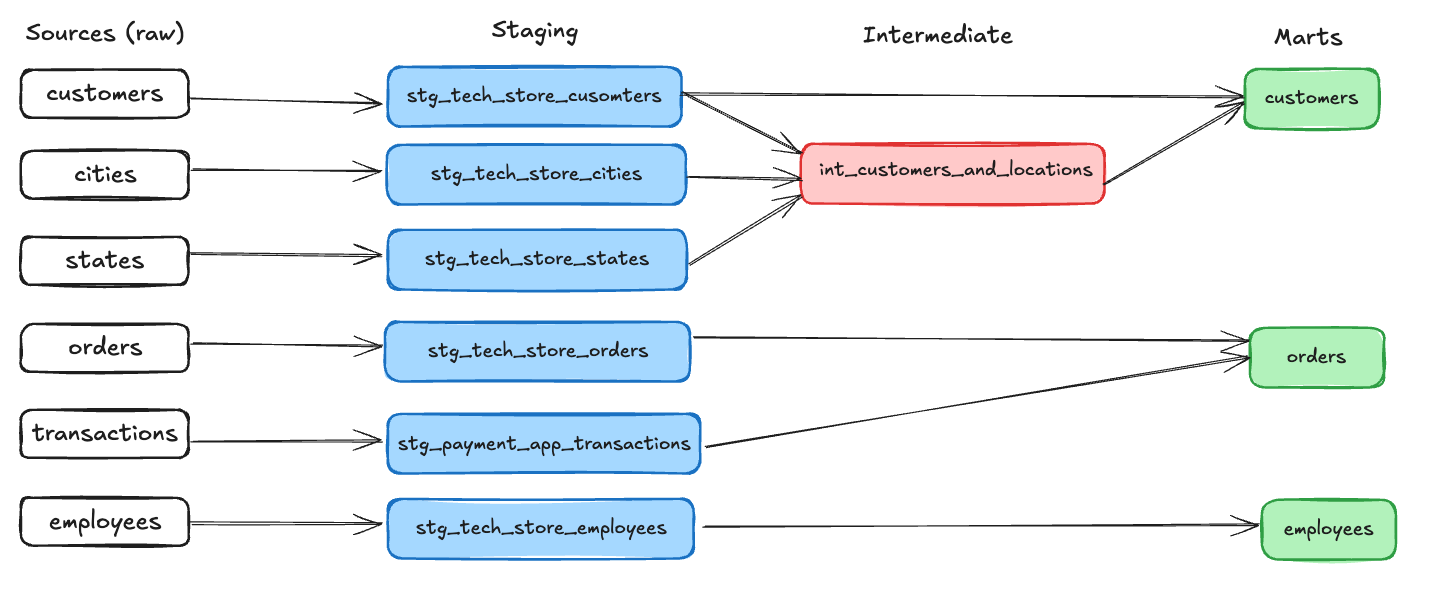
Entendido o conceito das três camadas, abaixo temos um exemplo de modelagem ponta a ponta desde as fontes de dados (sources) até os marts de clientes (customers), pedidos (orders) e colaboradores (employees).
Referências e leituras sobre este tema
Staging vs Intermediate vs Mart Models in dbt
Staging: Preparing our atomic building blocks
Intermediate: Purpose-built transformation steps
What are "intermediate" models in dbt?
Antes de você ir embora
Se quiser discutir mais sobre isso, fique à vontade para deixar um comentário ou entrar em contato comigo pelo LinkedIn.